0.目标:建设可观测监控体系
目前业界广泛推行的可观测数据包含三大支柱:日志事件(Logging)、链路追踪(Tracing)、指标监控(Metrics),其中存在一些共性需要关注。
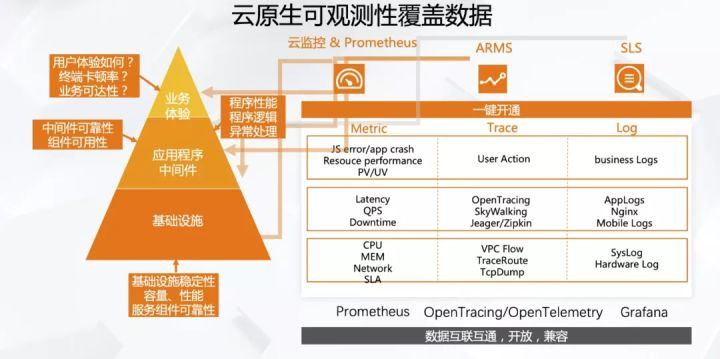
全栈覆盖
基础层、容器层、上方组建云服务应用,以及用户终端相应可观测数据以及与之对应的指标、链路、事件都需要被采集。
统一标准
整个业界都在推进标准统一,首先是指标(metrics),Prometheus作为云原生时代的指标数据标准已经形成了共识;链路数据的标准也随着 OpenTracing 和 OpenTelemetry 的推行而逐渐占据主流;在日志领域虽然其数据的结构化程度较低难以形成数据的标准,但在采集存储和分析侧也涌现了 Fluentd,Loki 等开源新秀;另一方面,Grafana 作为各种可观测数据的展示标准也愈加明朗
数据质量
数据质量作为容易忽视的重要部分,一方面,不同监控系统的数据源需要进行数据标准的定义,确保分析的准确性。另一方面,同个事件可能导致大量重复指标、告警、日志等。通过过滤、降噪和聚合,把具备分析价值的数据进行分析,保证数据质量的重要组成部分。这也往往是开源工具与商业化工具差距相对较大的地方。举个简单例子,当我们采集一条应用的调用链路,到底采集多深?调用链路采样的策略是什么样的?发生错、慢时是不是能够全部采下来?是不是能够基于一定规则对采样策略进行动态调整等等,都决定了可观测数据采集的质量。
统一展现
上面提到可观测需要覆盖各个层次,每层都有相应可观测数据。但目前可观测相关工具非常零散,如何将这些工具产生的数据统一展现出来,成了比较大挑战。可观测数据的统一其实是相对较难的事情,包括格式、编码规则、字典值等问题。但数据结果统一呈现是可以做到的,目前主流的解决方案是使用 Grafana,搭建像统一监控大盘。
协作处理
在统一展现以及统一告警之后,如何借助像钉钉、企业微信等协作平台能够更加高效地进行问题发现并处理跟踪的 ChartOps,也逐渐成为刚需。
1.基准指标设计
通过分析一些业内的监控方法框架发现:主要把监控指标分为硬件指标和服务指标,服务指标又分为中间件等工具服务和面向客户的业务服务(基本契合上述可观测性覆盖数据的监控逻辑)。同时黑盒监控方面采用探针的方式对服务进行拨测。
指标采集原则
黄金指标:
Four Golden Signals是Google针对大量分布式监控的经验总结,4个黄金指标可以在服务级别帮助衡量终端用户体验、服务中断、业务影响等层面的问题。主要关注与以下四种类型的指标:延迟,通讯量,错误以及饱和度。
RED方法
RED方法是Weave Cloud在基于Google的“4个黄金指标”的原则下结合Prometheus以及Kubernetes容器实践,细化和总结的方法论,特别适合于云原生应用以及微服务架构应用的监控和度量。主要关注以下三种关键指标:
- (请求)速率:服务每秒接收的请求数。
- (请求)错误:每秒失败的请求数。
- (请求)耗时:每个请求的耗时。 在“4大黄金信号”的原则下,RED方法可以有效的帮助用户衡量云原生以及微服务应用下的用户体验问题。
USE方法
USE方法全称"Utilization Saturation and Errors Method",主要用于分析系统性能问题,可以指导用户快速识别资源瓶颈以及错误的方法。正如USE方法的名字所表示的含义,USE方法主要关注与资源的:使用率(Utilization)、饱和度(Saturation)以及错误(Errors)。
- 使用率:关注系统资源的使用情况。 这里的资源主要包括但不限于:CPU,内存,网络,磁盘等等。100%的使用率通常是系统性能瓶颈的标志。
- 饱和度:例如CPU的平均运行排队长度,这里主要是针对资源的饱和度(注意,不同于4大黄金信号)。任何资源在某种程度上的饱和都可能导致系统性能的下降。
- 错误:错误计数。例如:“网卡在数据包传输过程中检测到的以太网网络冲突了14次”。
通过对资源以上指标持续观察,通过以下流程可以识别资源瓶颈:

指标采集方法
在上述理论的基础上,在采集时应当标准化采集四种黄金指标类型对应的指标并根据不同的目标使用相应的监控方法。RED方法侧重监控服务,USE方法侧重监控性能。
| 层级 | 指标维度 |
|---|---|
| 基础设施层级(网络、主机、容器、编排工具) | 资源用量、编排调度、错误 |
| 工具服务中间件 | 资源用量,服务状态、错误 |
| 应用(包括Library) | 延迟,错误,QPS,内部状态 |
在实际使用过程中应该减少关注基础设施层级的图表状态,只对某些场景下的指标做限制告警即可。换句话说基础设施的指标变化不是为业务可靠性改变的必要条件,但可以对某些预期事件做出预警,在use方法中对于基础设施指标的的依赖尤其明显,该方向的监控多在监控性能的维度发挥作用。
而对于工具服务中间件层级的指标监控在基础设施层级之上,该层级的特点是对应工具的方向性较强,在基础指标之上每个工具的指标选择个性化程度较大,比如:cdn的指标监控主要关注的是请求回源成功率,cdn流量计费等;而队列服务主要关注其队列消息堆积/积压情况;涉及缓存/持久化存储的服务还需主要关注存储容量的资源用量等,所以每个工具应定制化的进行指标采集与展示。
应该主要关注对应服务状态、和错误,在这一层级错误和成功率将作为一个重要指标进行监控。同时作为最上层应用,工具服务中间件等下层设施服务都会对其产生影响,服务粒度的基础指标收集同样重要。
具体基线指标:
| 层级 | 分组 | 指标看板 | 指标 | 示例 |
|---|---|---|---|---|
| 基础设施层级 | 主机 | ecs主机 k8s节点 |
CPU利用率、内存利用率、磁盘利用率、状态 | |
| 网络 | cdn网络 服务网络 |
IO统计、各地访问时延、dns解析状态、证书到期时间 | https://grafana.ops.jdydevelop.com/d/8-yRvLoMk/a-li-yun-wang-luo-jian-kong?orgId=1 | |
| 容器集群 | k8s集群基础大盘: Kubernetes Overview大盘 Deployment大盘 Pod大盘 Node Details大盘 |
CPU信息、内存信息、网络信息、磁盘信息等 | https://help.aliyun.com/document_detail/213786.html#section-myb-8y3-v91 | |
| 工具服务中间件 | 数据库 | mongos、secondary | CPU利用率、内存利用率 | https://grafana.ops.jdydevelop.com/d/XHlqJQwMz/shu-ju-ku-shu-ju-ku-fu-zai-zhuang-tai?orgId=1&refresh=10s |
| 消息队列 | rabbitmq | 节点身份,包括RabbitMQ&Erlang/OTP版本,节点内存磁盘利用率等 | https://grafana.ops.jdydevelop.com/d/Kn5xm-gZk/dui-lie-rabbitmqzong-lan?orgId=1&refresh=15s | |
| 缓存服务 | redis | 数据流量、对象数量、命中统计、操作频率、操作时间、内存信息、cpu信息 | https://grafana.com/grafana/plugins/redis-datasource/ | |
| 网关服务 | api gateway | 请求成功率 请求状态统计(4xx,5xx,200) | https://grafana.ops.jdydevelop.com/d/Rmeecw0nk/ingress-qing-qiu-jian-kang-zhuang-tai-tong-ji?orgId=1&refresh=10s | |
| office文件服务 | onlyoffice | IO读写、请求状态统计(4xx,5xx,200)、服务基础指标信息(容器内存、CPU负载) | https://grafana.ops.jdydevelop.com/d/HmjiRMTmz/office-wen-jian-yu-lan-fu-wu-zhuang-tai?orgId=1&refresh=10s | |
| 七牛 | qiniu | 网络IO统计、服务基础指标信息(容器内存、CPU负载) | https://grafana.ops.jdydevelop.com/d/svOVtkcmz/qi-niu-zhuan-fa-fu-wu-zhuang-tai?orgId=1&refresh=10s | |
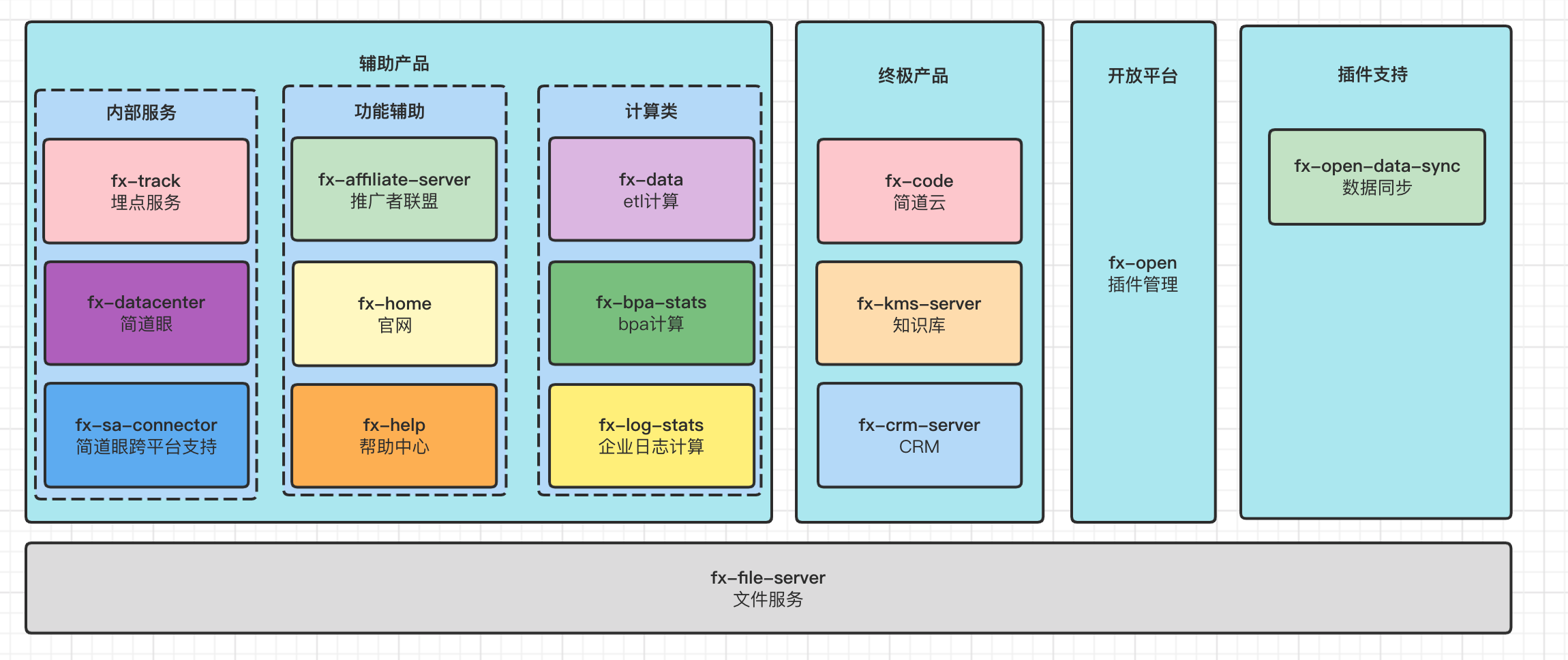
| 业务应用 | 简道云基础服务 | code(简道云)、kms-server(知识库)、crm-server(CRM) | QPS、请求时延、请求成功率、请求状态统计、服务基础指标信息(容器内存分布、CPU负载分布) | https://grafana.ops.jdydevelop.com/d/kruLJwQMz/jian-dao-yun-zong-lan?orgId=1&refresh=10s |
| 简道云内部服务 | track(埋点)、datacenter(简道眼)、sa-connector(跨平台) | QPS、请求时延、请求成功率、请求状态统计、服务基础指标信息(容器内存分布、CPU负载分布) | ||
| 简道云功能服务 | affiliate-server(推广者联盟)、home(官网)、help(帮助中心) | QPS、请求时延、请求成功率、请求状态统计、服务基础指标信息(容器内存分布、CPU负载分布) | ||
| 简道云计算类服务 | data(ETL计算)、bpa-stas(BPA计算)、log-stat(企业日志计算)、fileserver(文件服务) | QPS、请求时延、请求成功率、请求状态统计、服务基础指标信息(容器内存分布、CPU负载分布) | ||
| 插件及第三方 | open(插件管理)、open-data-sync(数据同步)、paas(第三方) | QPS、请求时延、请求成功率、请求状态统计、服务基础指标信息(容器内存分布、CPU负载分布) | ||
| SRE工具 | jenkins | https://grafana.dev.jdydevelop.com/d/9CWBz0PP/node-exporter-for-jenkins?orgId=1 | ||
| argocd | ||||
| jira |
2.日志分析设计
现行方案
应用服务直接发送日志到graylog,loki,sentry。graylog接收日志流并存储到Elasticsearch中。通过列存储、倒排索引等方法提高查询速度。在目前使用上可以满足日志实时查询统计的需要。但改方案的缺点在于对于聚合等olap场景的日志支持不足,通常情况下分析工作需要其他工具进行预处理。同时在使用的loki采用压缩后hash的方式存储,虽然也采用了列存来加快查询速度,在某些场景下可以满足实时查询的需要,但是其功能主要用来日志快速检索过滤简单分析,不适合大数据存储和大规模索引的场景。特点是存储成本低,简单查询速度快,但是涉及到聚合遍历等olap数据分析响应较慢。sentry则更倾向于从日志发现服务问题,收集层代码的崩溃信息作为排障工具应用。
架构对比
Local Storage + Pssh扫描派(代表作:跳板机上各种脚本)
在Unix设计哲学中,没有什么是不能用管道完成的。十年前没有大数据概念的时候,日志对研发而言就是随时抛弃,偶尔查问题需用一用。因此设定一定大小回滚策略+Pssh就是最不折腾的选择,所以我们在跳板机上经常能看到各种封装的shell脚本,只需要几个参数就能快速检索。方法简单粗暴,带来的局限性也挺多,例如磁盘坏数据丢失、速度慢、对线上有性能影响等。非集中式日志检索技术随着大数据兴起,使用场景逐步在萎缩。
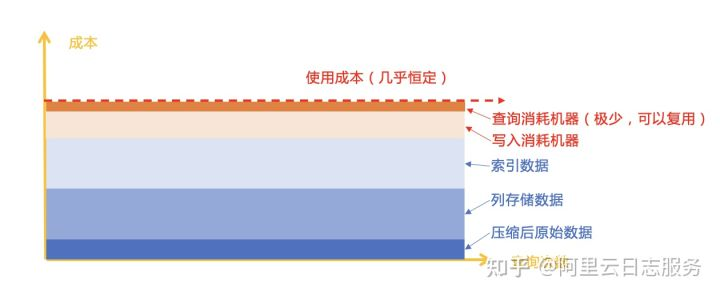
Central Storage + Inverted Index派(代表作:ES)
我们来看看ES成本模型,ES 模式是通过预处理生成索引,把之后检索变成常数级操作。ES存储构成为:原始数据(正排)、倒排索引(Inverted Index)、列存储(DocValue)3种类型。数据流入时需要消耗部分机器来对数据进行编码,但在查询时只需要消耗少量的资源便可快速找到数据。之后无论多少次查询,实际成本几乎是不变的。但带来的副作用是数据膨胀,例如AWS在ES使用建议上,一般推荐预留2-3倍的空间来应对数据存储(在2 Replica情况下)
 Central Storage + Column Storage + MR派(代表作:Hive)
Hadoop出现提供了HDFS分布式存储引擎,而Hive/Spark等MR引擎为了加快执行速度,天然集成了Column Storage(列存储类型),Column Storage对于类型固定的列有良好的压缩率,例如可以通过Delta、Dictionary等编码技术压缩原始数据大小,当查询时通过Histogram进行快速跳转。Column Storage对OLAP计算很友好,数据量小又能做启发式搜索。ES在五年前也推出了Column Storage类似的Doc Value技术,可以通过ES API来对列数据进行分析。Column Storage一般会搭配一个计算引擎,基于MR的Hive、Spark提供基于磁盘的外排能力,除了执行速度慢一些之外,几乎能够胜任所有的SQL92查询分析需求。
Central Storage + Column Storage + MPP派(代表作:ClickHouse)
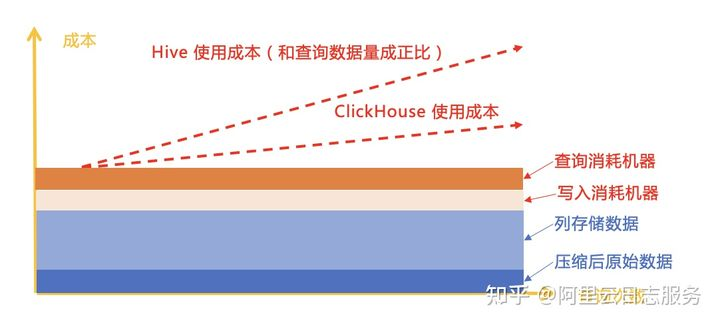
MR方案可以通吃从小到大的各类场景,但带来的缺点是速度不够快,并发不高,不适合实时性高的场景。之后Druid、Presto等MPP引擎诞生通过内存来代替磁盘交换,把Query执行速度大大提升。最近2年ClickHouse横空出世吸引了不少粉丝,ClickHouse秉承俄罗斯人的简单粗暴出奇迹特点,把用Hand Craft计算发挥得淋漓尽致。虽然ES也在向OLAP领域进军,ClickHouse未来也会做倒排索引,但这背后存在一个不争的事实。日志分析除了日志的TP,也会有少量的AP情况需要混合考虑。Hive和MPP成本模型如下,数据写入一般需要前端机对数据进行转换,在读取时需要对数据进行排序过滤等,消耗一部分计算资源。
Central Storage + Column Storage + MR派(代表作:Hive)
Hadoop出现提供了HDFS分布式存储引擎,而Hive/Spark等MR引擎为了加快执行速度,天然集成了Column Storage(列存储类型),Column Storage对于类型固定的列有良好的压缩率,例如可以通过Delta、Dictionary等编码技术压缩原始数据大小,当查询时通过Histogram进行快速跳转。Column Storage对OLAP计算很友好,数据量小又能做启发式搜索。ES在五年前也推出了Column Storage类似的Doc Value技术,可以通过ES API来对列数据进行分析。Column Storage一般会搭配一个计算引擎,基于MR的Hive、Spark提供基于磁盘的外排能力,除了执行速度慢一些之外,几乎能够胜任所有的SQL92查询分析需求。
Central Storage + Column Storage + MPP派(代表作:ClickHouse)
MR方案可以通吃从小到大的各类场景,但带来的缺点是速度不够快,并发不高,不适合实时性高的场景。之后Druid、Presto等MPP引擎诞生通过内存来代替磁盘交换,把Query执行速度大大提升。最近2年ClickHouse横空出世吸引了不少粉丝,ClickHouse秉承俄罗斯人的简单粗暴出奇迹特点,把用Hand Craft计算发挥得淋漓尽致。虽然ES也在向OLAP领域进军,ClickHouse未来也会做倒排索引,但这背后存在一个不争的事实。日志分析除了日志的TP,也会有少量的AP情况需要混合考虑。Hive和MPP成本模型如下,数据写入一般需要前端机对数据进行转换,在读取时需要对数据进行排序过滤等,消耗一部分计算资源。
 Central Storage + 扫描类(代表作:Grafana-Loki)
扫描压缩后的原始数据,看起来像是“返璞归真”的技术退化。但似乎又是一种顺应时代的做法。这个方案典型的代表是Grafana旗下Loki。Grafana因为没有存储技术的积累,因此光脚不怕穿鞋的,直接出了一个将日志直存对象存储 + 扫描方案。这个背后的理由也说的过去,云存储是未来是能够保证持续间隔竞争力的,而大部分日志是写多读少的,在一些场景下慢一些似乎也没什么差别,实际使用过程中应避免扫描方法的语句(慢查询)。
Central Storage + 扫描类(代表作:Grafana-Loki)
扫描压缩后的原始数据,看起来像是“返璞归真”的技术退化。但似乎又是一种顺应时代的做法。这个方案典型的代表是Grafana旗下Loki。Grafana因为没有存储技术的积累,因此光脚不怕穿鞋的,直接出了一个将日志直存对象存储 + 扫描方案。这个背后的理由也说的过去,云存储是未来是能够保证持续间隔竞争力的,而大部分日志是写多读少的,在一些场景下慢一些似乎也没什么差别,实际使用过程中应避免扫描方法的语句(慢查询)。
综合对比
- 存储成本:Loki存储是裸数据,经过压缩后理论上空间是最小的。ES存储内容最多,因此存储成本比较高。而Hive、ClickHouse因只有列存,相对较小(对于比较随机的纯文本数据,列存理论上和字符串压缩接近)。
- 分析能力:Hive支持完整SQL92,并且没有计算量的限制,分析能力最强。ClickHouse支持的是有限SQL集,对常见的场景足够用。接下来是ES、Loki最弱。
- 查询速度:在建立索引情况下,ES是当之无愧的王者。基于MPP引擎的ClickHouse次之(对于带计算的分析,ClickHouse是最强的)。
- 分析成本:Loki最高,读取数据后大部分工作都需要外围完成。
- 查询成本:ES读取数据量最少,因此最优,接下来是ClickHouse,Hive和Loki。
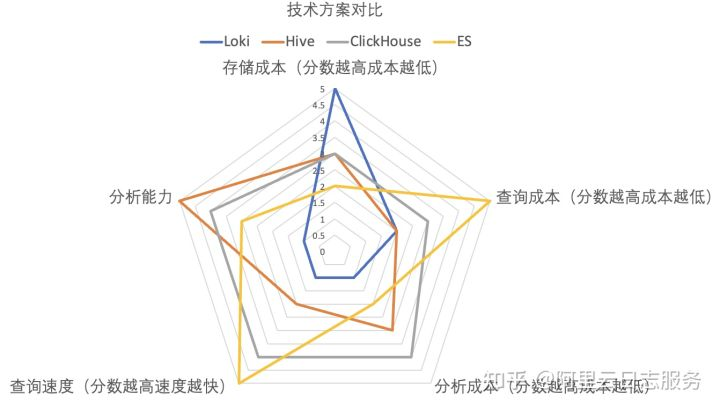
从需求角度而言,是否有一种更综合架构?
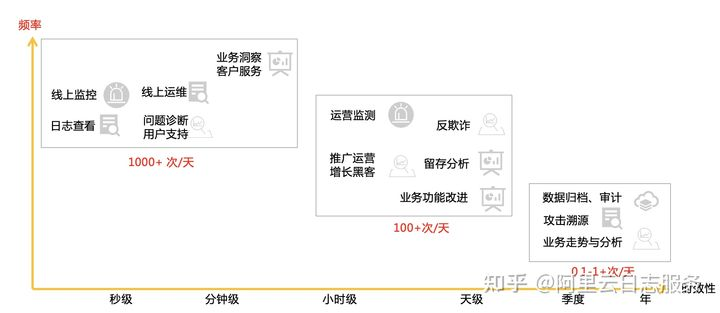
为什么会有这么多的选择呢?主要是由二个因素决定的:处理需求 vs 实现成本。我们先从需求出发,看看业务需要什么? 对Nginx、App访问日志而言,一般有如下典型用途:
- 第一阶段(数据产生1分钟内):程序要看到实时业务,运营客服人员需要查看轨迹定位问题。这种场景一般都在小时内, 查询频率比较高。
- 第二阶段(数据产生1-2小时左右):业务需要洞察数据,一般都是小时级或天级别。查询频率一般,往往也都是针对于聚合后的数据。
- 第三阶段(一天后):审计需要,业务需要看趋势数据。查询频率比较低,往往是点查(例如回溯一个历史问题)。
第一阶段:实时性和延时更重要
这个阶段数据实时性变得无比重要,例如用户付款投诉时,我们需要快速通过TraceId来定位后台的用户行为。我们需要根据业务访问的QPS、下单率等快速在日志中找到错误日志。需要根据业务流量情况、趋势来调度资源。 典型的访问如下:
| 访问模式 | 对实时性的要求 | 对延时的要求 | 访问频率 | 技术选型 |
|---|---|---|---|---|
| 查询所有访问记录中,负责某些条件的请求Latency>5000 and Host:http://www.example.com | <1 分钟 | 秒级 | 出问题后较高 | ES |
| 对查询结果进一步Drill Down,进行统计分析Latency>5000 and Host:http://www.example.com select top10 userid | <1 分钟 | 秒级 | 出问题后较高 | ES、ClickHouse |
| 统计当前访问量的趋势,并对异常情况做告警select sum(1) as qps, avg(Latency) as l, p99(Latency) as p, time_windows(t, ‘second’) as t group by t desc | <5 秒 | <秒级 | 较高 | TSDB,ClickHouse |
| 查询某个用户,或某个TraceId情况TraceId:12345 | 分钟级 | <秒级 | 较高 | ES |
可以发现该阶段大部分分析都是集中在最近5分钟时间内的数据,这些数据会被频繁访问到,并且Query条件变化范围会非常大。比较典型组合是TSDB/NoSQL/SQL + ES + ClickHouse,存储和计算成本会稍微大一些
第二阶段(天级):比拼分析能力
第二个阶段业务需求会更复杂,这个阶段主要面向的是精细化需求。例如从延时、成功率等指标去度量接口稳定性,服务质量等。运营根据数据对比来发现群体特征,用来构筑质量体系等。运营会根据数据来确定投放、牵引等策略。 这个阶段访问模式包含两种:
| 访问模式 | 对延时的要求 | 访问频率 | 技术选型 |
|---|---|---|---|
| 根据某个Key查询已计算好的数据,例如用户特征等 | 越快越好,秒级 | 百万次 | 计算后存储ClickHouse、Hbase、MySQL等进行访问 |
| 根据灵活需求透视数据 | 秒级、分钟级 | 几十次/天 | ClickHouse,Hive |
第三阶段(月级):比拼成本
这个阶段数据的访问往往两极分化:趋势型分析,一般可以通过预处理技术提前降低数据量来解决。大规模数据的统计、大规模数据中查找极小部分数据。后者一般发生的概率非常低,但每次几乎都是突发需求,如果能在较短的延时内获得结果对体验是最好的。
| 访问模式 | 对处理延时的要求 | 访问频率 | 技术选型 |
|---|---|---|---|
| 对长时间、大数据进行分析 | 无 | 几次/天 | Hive |
| 查看长时间趋势性数据 | 秒级 | 十几次/天 | 预计算后存储Hbase、MySQL后访问 |
| 应对突发查询需求,例如查询某个用户长时间行为 | 分钟基-小时级 | 较低 | ES、写程序Scan |
| 应对突发导数据需求,将某些数据导出到其他位置 | 小时级 | 较低 | Hive、写程序Scan |
定量分析
可以发现loki在分钟级故障分析的性价比极高推荐搭配对象存储作为私有云日志分析存储方案

3.链路跟踪设计
监控中少不了依赖关系和调用链,它可以帮助我们快速的定位应用在哪个服务环节出了问题,哪些地方可以优化。CNCF 提出了分布式追踪的标准 OpenTracing(新的叫OpenTelemetry)它提供用厂商中立的 API,并提供 Go、Java、JavaScript、Python、Ruby、PHP、Objective-C、C++ 和 C# 这九种语言的库。大部分分布式追踪系统都是根据 Google 的 Dapper 论文 实现的,比如 CNCF 中还有个端到端的支持 OpenTracing API 的分布式追踪项目 Jaeger。另外 Apache 基金会项目也有个中国开源的应用性能监控工具 SkyWalking 也可以实现分布式追踪。比较热门的几个链路跟踪的开源项目还包括zipkin。
什么是链路跟踪:分布式链路追踪所监控的对象就是一次次调用所产生的链路(Trace),系统会通过唯一的标识(TraceId)对此进行记录。而链路中的每一个依赖调用都会生成一个调用踪迹信息(Span),最开始生成的Span叫做根Span(Root Span),后续生成的Span都会将前一个Span 的标示(Sid)作为本Span信息的父ID(Pid)。 这样以此类推,Span信息就会随着链路的执行被进程内或跨进程进行上下文传递,通过Span数据链就能将一次次链路调用所产生的踪迹信息串联起来,而每一个Span之上附着的日志信息(Annotation)就是我们进行调用链监控分析的数据来源。这就是分布式链路追踪的基本原理,
附:应用对比图
 链路追踪工具虽可解决链路监控问题、完善监控体系,但涉及不同程度的代码入侵,必要性和实践成本有待评估。
暂不选型对比设计。
链路追踪工具虽可解决链路监控问题、完善监控体系,但涉及不同程度的代码入侵,必要性和实践成本有待评估。
暂不选型对比设计。
4.告警设计原则
基于实践序列进行有效报警
时间序列有效报警由《google sre 运维解密》阐述并应用于borgmon谷歌内部监控系统,就是取代以往探针模型(脚本测试检查回复并报警),建立在时间序列之上,以标签化向量的方式存储监控数据的监控告警体系。本质上感觉和prometheus监控体系差不多。
当前告警框架:
当前告警规则:
https://docs.ops.jdydevelop.com/production/05.monitoring/
告警设计原则
基础四个黄金指标
尽量简化
•那些最能反映真实故障的规则应该越简单越好,可顶测性强,非常可靠。 •那些不當用的数据收集、汇总,以及警报配置应该定时制除(某些 SRE团队的标准是一个季度没有用到一次即將其删除)。 •收集到的信息,但是没有暴露给任何监控台,或者被任何警报规贝使用的应该定时删除
合适的精度
应该仔细设计度量指标的精确度。每秒收集 CPU 负载信息可能会产生一些有意思的数据, 但是这种高频率收集、存储、分析可能成本很高。如果我们的监控目标需要高精度数据 但是却不需要极低的延迟,可以通过一些内部采样机制外部汇总的方式降低成本 例如:(bucket桶策略等) 1.将当前 CPU 利用率按秒记录 2.按5%粒度分组,将对应的 CPU 利用率计数 +1。 3.将这此值每分钟汇总一次 这种方式使我们可以观测到短暂的 CPU热点,但是又不需要为此付出高额成本进行收集和保留高精度数据。
总体思路
- 每当收到紧急警报时,应该立即需要我进行某种操作。每天只能进人繁急状态几次,太多就会导致 “狼来了”效应。
- 每个紧急警报都应该是可以具体操作的。
- 每个紧急警报的回复都应该需要某种智力分析过程。如果某个紫急警报只是需要
- 个固定的机械动作,那么它就不应该成为紧急警报,
- 每个紧急警报都应该是关千某个新问题的,不应该彼此重叠
监控系统的长期维护
忽略屏蔽掉需要根治的问题,并及时跟进根因问题和相关任务。可预知的脚本干预(利用脚本解决一些不必要的告警,比如升级前可先将告警规则屏蔽)。
5.框架分析
在一些大公司的监控及日志收集模块是和数据分析系统集成在一起的衍生出来企业数据中台兼具分析功能,但基础无非都是用户日志收集。
美团大数据平台
数据源来自MySQL数据库和日志,数据库通过Canal获得MySQL的binlog,输出给消息队列Kafka,日志通过Flume输出到Kafka。Kafka的数据会被流式计算和批处理计算两个引擎分别消费。流处理使用Storm进行计算,结果输出到HBase或者数据库。批处理计算使用Hive进行分析计算,结果输出到查询系统和BI(商业智能)平台。美团大数据平台的整个过程管理通过调度平台进行管理。公司内部开发者使用数据开发平台访问大数据平台,进行ETL(数据提取、转换、装载)开发,提交任务作业并进行数据管理。
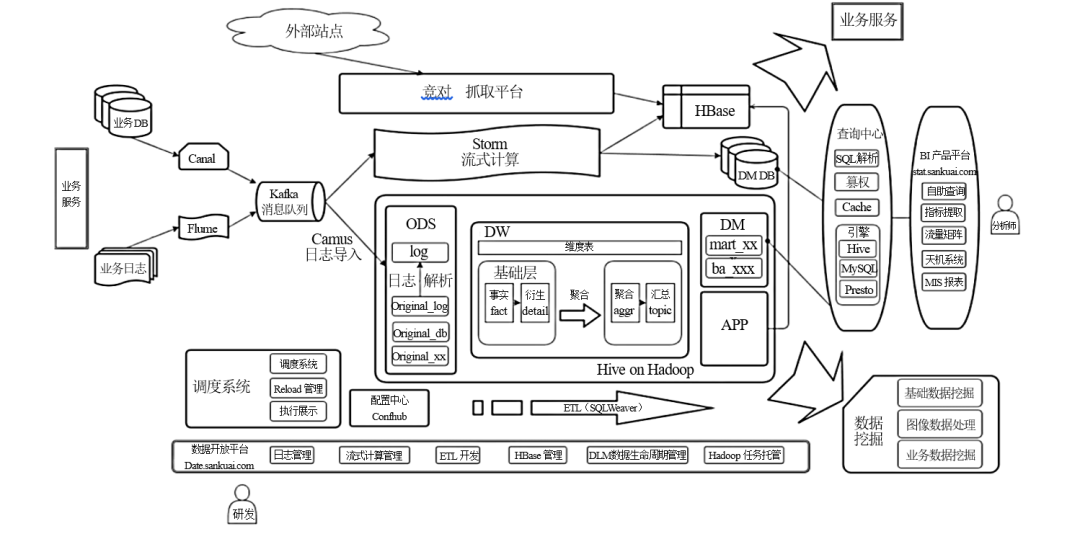
滴滴
滴滴大数据平台分为实时计算平台(流式计算平台)和离线计算平台(批处理计算平台)两个部分。
实时计算平台架构如图。数据采集以后输出到Kafka消息队列,消费通道有两个,一个是数据ETL,使用Spark Streaming或者Flink将数据进行清洗、转换、处理后记录到HDFS中,供后续批处理计算;另一个通道是Druid,计算实时监控指标,将结果输出到报警系统和实时图表系统DashBoard
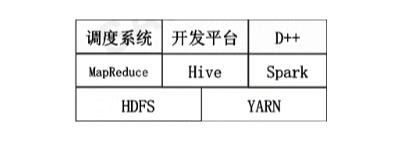
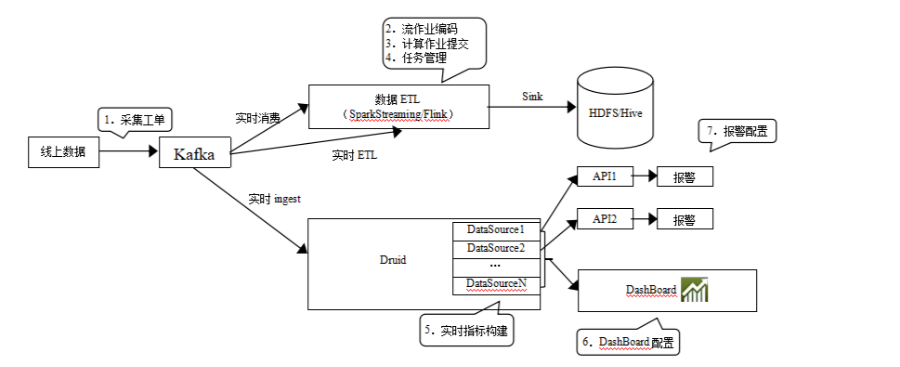 离线计算平台架构下图所示。滴滴的离线大数据平台是基于Hadoop 2(HDFS、Yarn、MapReduce)和Spark以及Hive构建的,并在此基础上开发了自己的调度系统和开发系统。调度系统和前面其他系统一样,调度大数据作业的优先级和执行顺序。开发平台是一个可视化的SQL编辑器,可以方便地查询表结构、开发SQL,并发布到大数据集群上。
离线计算平台架构下图所示。滴滴的离线大数据平台是基于Hadoop 2(HDFS、Yarn、MapReduce)和Spark以及Hive构建的,并在此基础上开发了自己的调度系统和开发系统。调度系统和前面其他系统一样,调度大数据作业的优先级和执行顺序。开发平台是一个可视化的SQL编辑器,可以方便地查询表结构、开发SQL,并发布到大数据集群上。
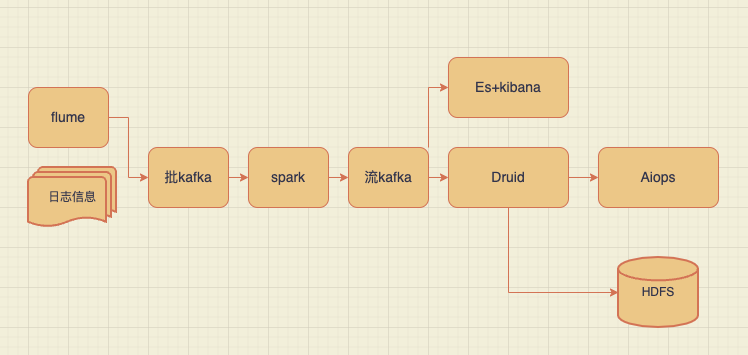
华为
flume做全量日志收集,传递到批kafka,spark做格式化处理,再由流kafka分发到各个平台,druid作数仓进行存储及实时计算和指标构建并投送到运维大盘,日志展示使用ES+kibana实现实时查询。
&参考: 《SRE google 运维解密》 https://baijiahao.baidu.com/s?id=1710858944699539993&wfr=spider&for=pc https://zhuanlan.zhihu.com/p/447698341 https://zhuanlan.zhihu.com/p/113159739 https://zhuanlan.zhihu.com/p/396211457 https://www.modb.pro/db/234456 https://jishuin.proginn.com/p/763bfbd3b156 #监控